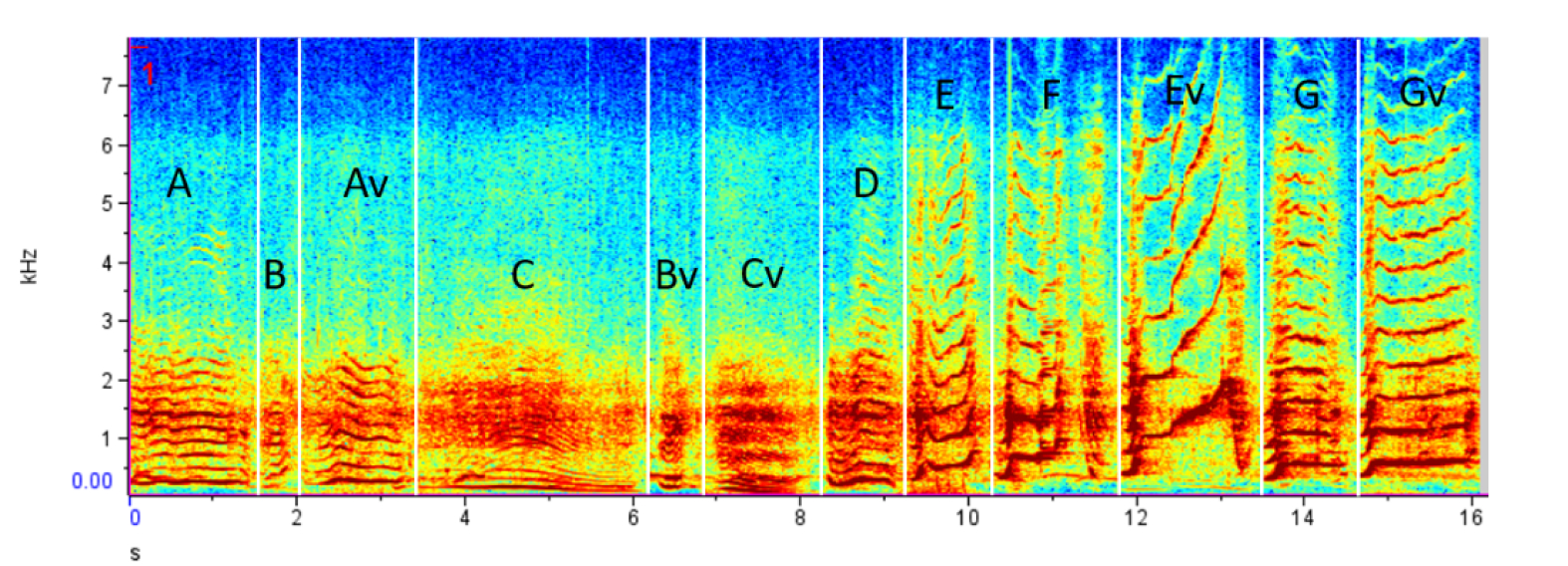
Robustness Through Noise Suppression
Our models incorporate sophisticated signal processing to isolate target vocalisations even within complex, noisy soundscapes. This ensures data integrity regardless of environmental conditions or equipment limitations.
Adaptive Learning for Precision
Transfer learning and fine-tuning methodologies allow models to be rapidly adapted to new environments or species. To detect new species, we only need a few hundred annotations of existing sounds.
Speed
Our models are really quick, allowing us to review acoustic data 400 times as fast as a human. This also means that our models can run in real time.
Interdisciplinary Expertise
Our team combines a deep understanding of acoustic principles, real-world signal acquisition experience, and cutting-edge machine learning techniques. This ensures solutions that effectively address the challenges of diverse acoustic environments.
Modular Design for Customization
Our framework utilises interchangeable audio representations, processing algorithms, and model types. This enables us to tailor pipelines precisely to your specific dataset and analysis requirements.
Scalability for Big Data
Our solutions are architected for distributed processing, gracefully handling large-scale acoustic datasets. Analys vast amounts of data without compromising efficiency or performance.